n8n 教學 (四):建立 n8n 工作流塞爆向量資料庫
發布日期:2025年5月
前言
理論準備完畢,現在是動手實作的時刻!本章節是系列教學的核心,我們將整合前幾章的成果,從無到有建立一個完整的 n8n 工作流。這個工作流會自動讀取指定的資料,透過 Gemini API 將其轉換為向量 (Embeddings),最後存入我們在 Supabase 中建立的向量資料庫。讓我們開始吧!
重要提醒: 如果您的 API key 綁定在免費方案
(free tier) 且未啟用帳單,則 Gemini 經手的資料就有可能被作為訓練用,如有機敏資訊,並且一定要使用 Gemini 的話,請務必升級至付費方案,或使用地端
LLM,亦或是公司提供的 API。
步驟一:建立與設定工作流
回到 n8n 點選 Create Workflow 建立第一個工作流,並完成基本設定。
- 點擊左上角重新命名工作流為
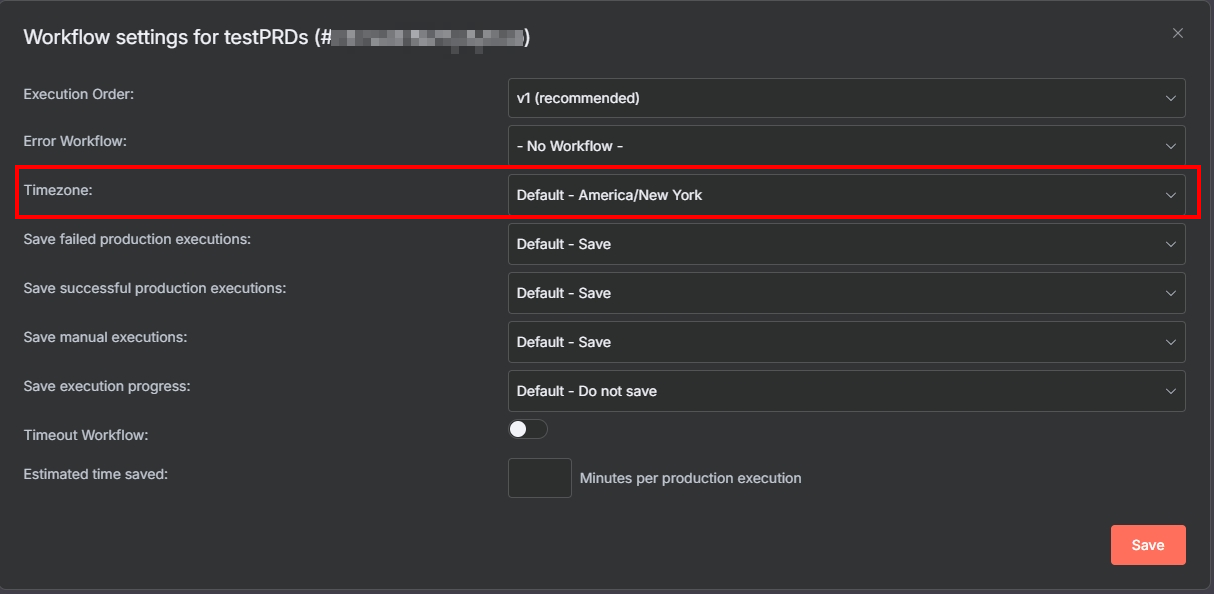
n8nDocIntoVectorDB。 - 點擊右上角 "..." 選單,進入 "Settings"。
- 將 "Time Zone" 改為 "Asia/Taipei" 後儲存。
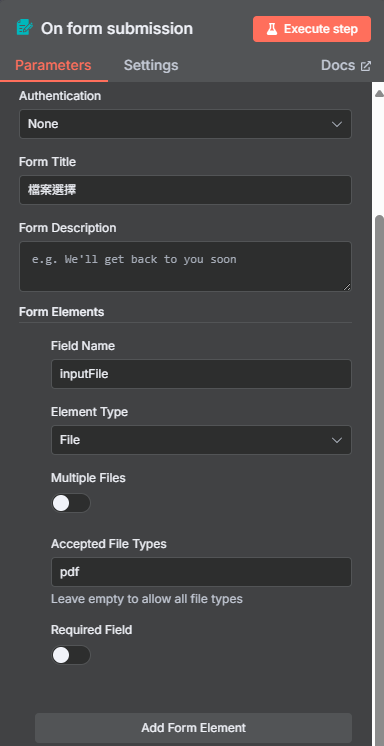
步驟二:設定 n8n Form 觸發器
我們將建立一個表單,讓使用者可以上傳 PDF 檔案作為觸發。
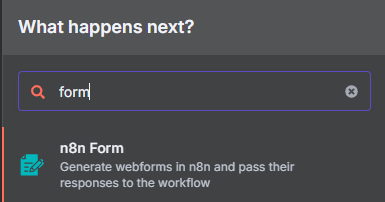
- 點選 "Add first step",搜尋並選擇 "n8n Form",事件為 "On new n8n Form event"。
- 將 "Form Title" 輸入「檔案選擇」。
- 點擊 "Add Form Element",並進行以下設定:
- Field Name:
inputFiles(注意大小寫) - Element Type: File
- Multiple Files: 關閉 (撥到左邊)
- Accepted File Types:
pdf
- Field Name:
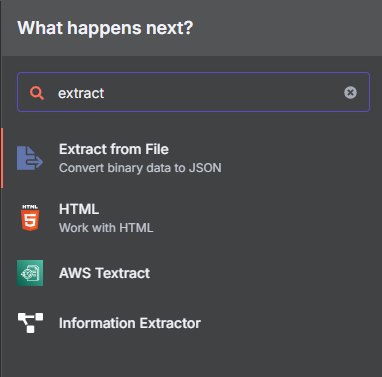
步驟三:從 PDF 提取文字
上傳檔案後,我們需要從中提取純文字內容。
- 在表單節點後新增節點,搜尋 "extract" 並選擇 "Extract from File",事件為 "Extract from PDF"。
- 在 "Input Binary Field" 欄位,將其從預設的
data改為inputFiles,對應我們在表單中設定的欄位名稱。
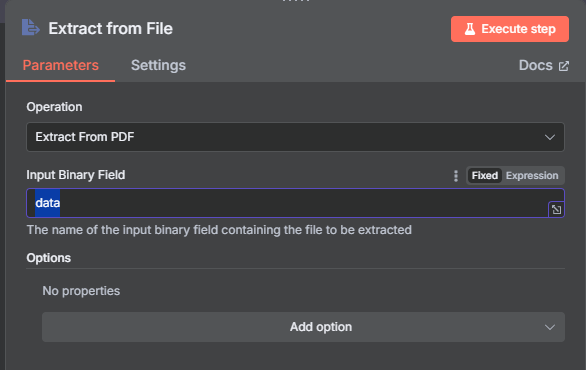
inputFiles
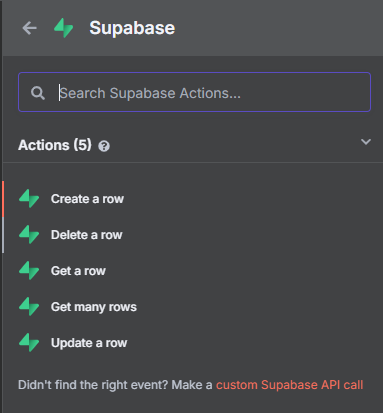
步驟四:(可選) 刪除舊資料
為了避免重複寫入,我們可以在寫入新資料前,先刪除同檔名的舊資料。
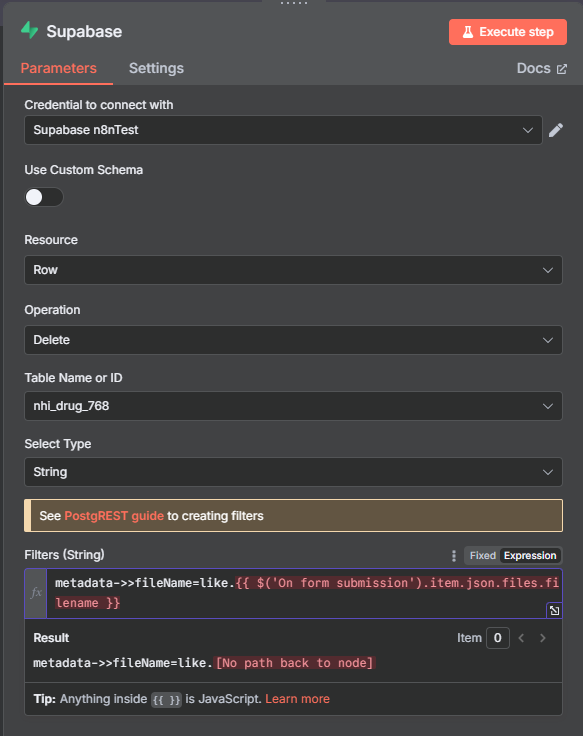
- 在 "Extract from File" 節點後新增 "Supabase" 節點,操作選擇 "Delete a row"。
- 選擇您的 Supabase 憑證,並將 "Table Name" 設為
nhi_drug_768。 - "Select Type" 選擇 "String"。
- 在 "Filters (String)" 欄位貼上以下表達式,並啟用 "Expression":
metadata->>fileName=like.{{ $('On form submission').item.json.inputFile.filename }}
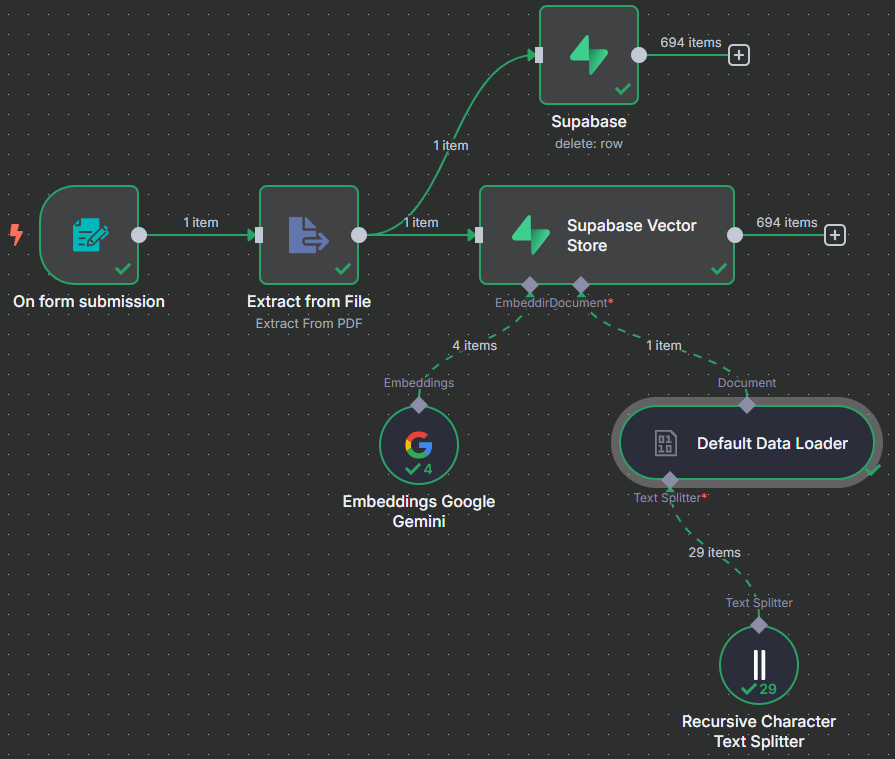
步驟五:寫入 Supabase Vector Store
這是最關鍵的一步,我們會將文字轉換為向量並存入資料庫。
- 在 "Delete a row" 節點後 (如果有的話,否則在 "Extract from File" 後) 新增 "Supabase Vector Store" 節點,操作選擇 "Add documents to vector store"。
- 選擇或建立您的 Supabase 憑證。
- "Table Name" 選擇
nhi_drug_768,"Query Name" 改為match_nhi_drug_768。 - 設定 Embedding Model:
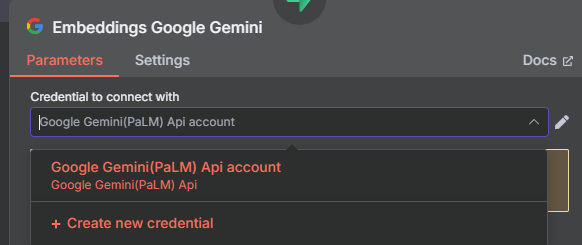
- 點擊節點左下的 "鬚鬚",選擇 "Embeddings Google Gemini"。
- 選擇或建立您的 Gemini API Key 憑證。
- Model 選擇
models/text-embedding-004。
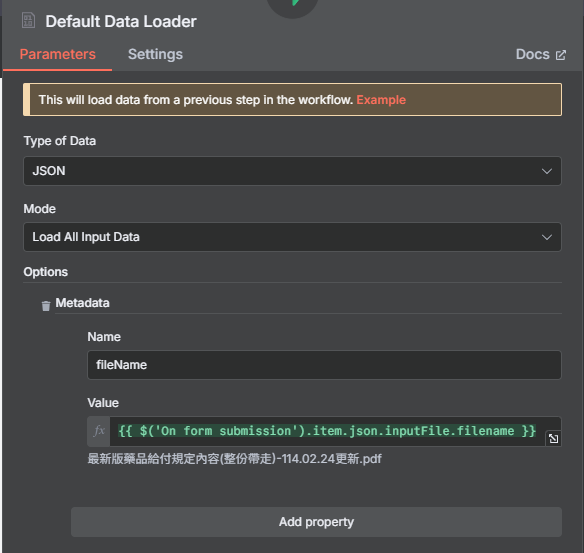
- 設定 Data Loader:
- 點擊節點右下角的 "鬚鬚",選擇 "Default Data Loader"。
- 點擊 "Add Option" -> "Metadata"。
- 點擊 "Add property",Name 輸入
fileName,Value 貼上表達式{{ $('On form submission').item.json.inputFile.filename }}。
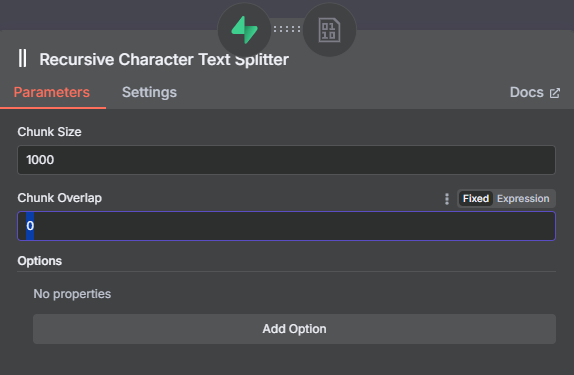
- 設定 Text Splitter:
- 點擊右下角鬚鬚的 "+",選擇 "Recursive Character Text Splitter"。
- 將 "Chunk Size" 改為
200。
步驟六:執行與驗證
一切就緒!讓我們來執行工作流並驗證結果。
- 點擊右上角的 "Execute workflow"。
- 在彈出的表單中,選擇一個 PDF 檔案並點擊 "Submit"。 (示範檔案可至 健保署網站下載)
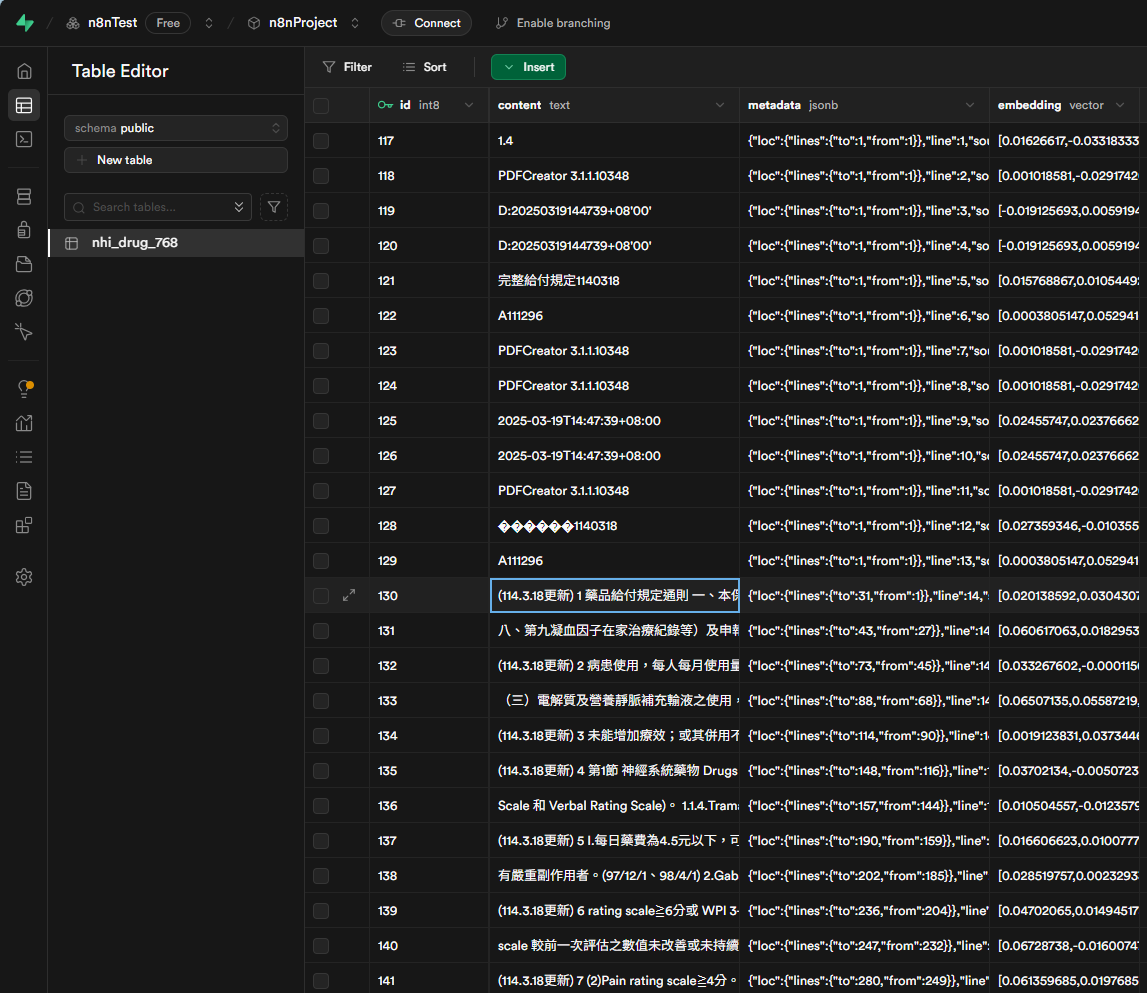
- 工作流會自動執行。執行完畢後,回到您的 Supabase 專案。
- 打開 "Table Editor",查看
nhi_drug_768資料表,您應該能看到剛剛上傳檔案的內容已經被切割並寫入。
本章總結
恭喜您!您已經成功建立並執行了第一個結合 AI 的 n8n 自動化工作流。在本章中,我們學會了:
- 如何透過 n8n Form 觸發工作流並接收檔案。
- 從 PDF 檔案中提取文字內容。
- 在寫入前刪除舊資料,避免重複。
- 設定 Supabase Vector Store,包含 Embedding、Metadata 與 Text Splitter。
- 將整個流程串聯起來,並成功將檔案內容寫入向量資料庫。
現在您已經掌握了將資料 "存入" 向量資料庫的技巧。在最後一篇教學中,我們將探討如何 "取出" 這些資料,讓 AI 參考向量資料庫的內容來回答問題,完成一個簡易的 RAG (Retrieval-Augmented Generation) 應用。