n8n 教學 (五):讓 AI 參考向量資料庫回答 (RAG)
發布日期:2025年5月
最終章:打造您的第一個 RAG 應用
歡迎來到 n8n 教學系列的最終篇!在前面的章節中,我們學會了如何將資料存入向量資料庫。現在,我們要來學習如何「利用」這些資料。本章將引導您建立一個完整的 RAG (Retrieval-Augmented Generation) 工作流,讓 AI 能夠根據您提出的問題,從 Supabase 中檢索最相關的資訊,並生成精準的回答。
重要提醒: 如果您的 API key 綁定在免費方案
(free tier) 且未啟用帳單,則 Gemini 經手的資料就有可能被作為訓練用,如有機敏資訊,並且一定要使用 Gemini 的話,請務必升級至付費方案,或使用地端
LLM,亦或是公司提供的 API。
步驟一:設定聊天觸發器
首先,建立一個新的工作流,並選擇以聊天訊息作為觸發方式。
- 建立一個新工作流,命名為
n8nChatWithAI。 - 選擇觸發器時,點選 "On chat message"。這會讓工作流在您透過聊天介面傳送訊息時啟動。
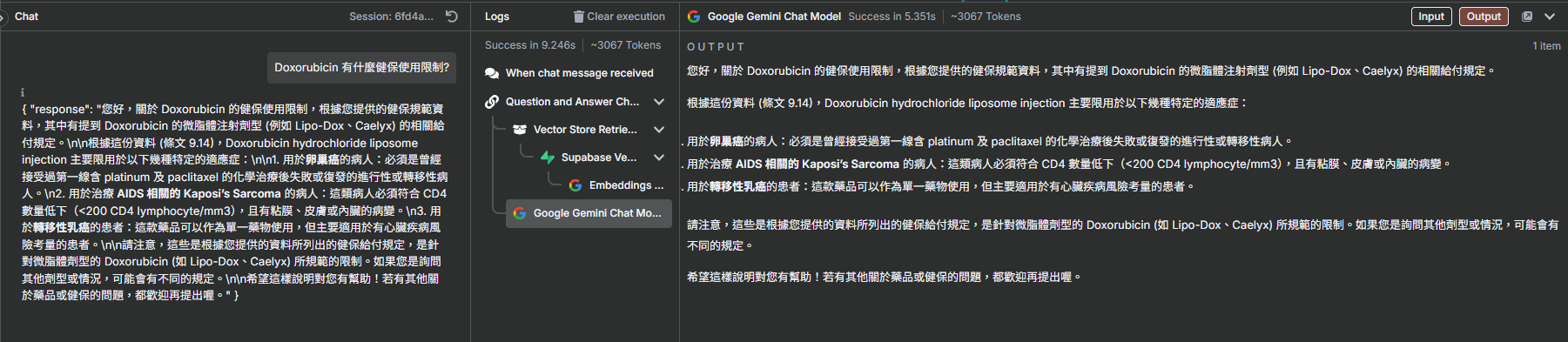
步驟二:加入問答鏈 (Q&A Chain)
接下來,我們加入一個核心元件 "Question and Answer Chain",它會幫我們整合後續的語言模型和向量資料庫。
- 在觸發器後新增節點,搜尋 "question" 並選擇 "Question and Answer Chain"。
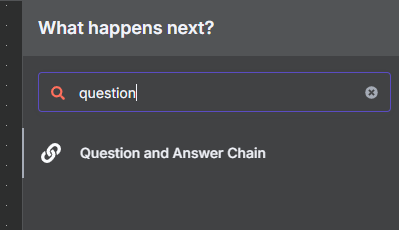
- 點擊 "Add Option" 並選擇 "System Prompt Template",讓我們可以客製化 AI 的指令。
- 啟用 "Expression" 並貼上以下提示詞,為 AI 設定角色和任務:
你是專業藥劑師,專長是台灣健保給付規範相關領域。 閱讀 Vector Store 的健保規範資料庫,了解台灣健保的相關規範,並以專業藥劑師的角度親切地回答使用者問題。 一律用繁體中文回應,但英文專有名詞則保留原文。 Context: {context}
步驟三:設定大型語言模型 (LLM)
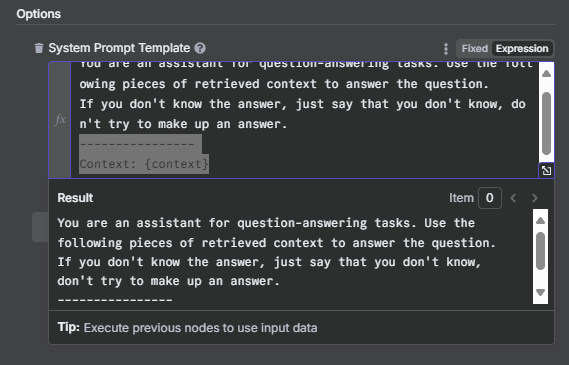
現在,我們要為 Q&A Chain 指定一個大腦,也就是我們選用的語言模型。
- 點擊 Q&A Chain 節點左下的 "鬚鬚"。
- 選擇 "Google Gemini Chat Model"。
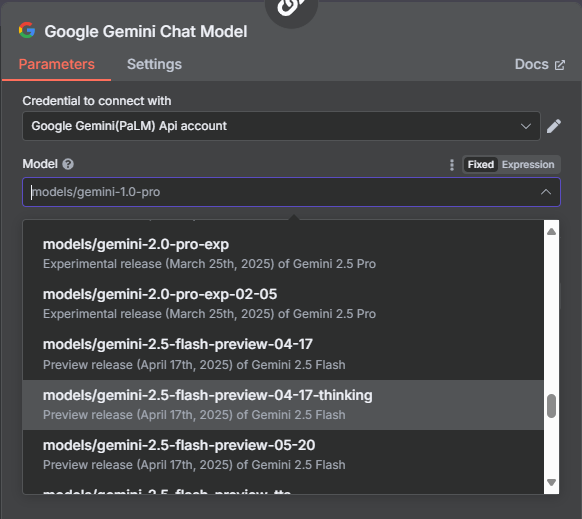
- 選擇或建立您的 Gemini 憑證,並將 Model 選為
models/gemini-2.5-flash(或您偏好的模型)。
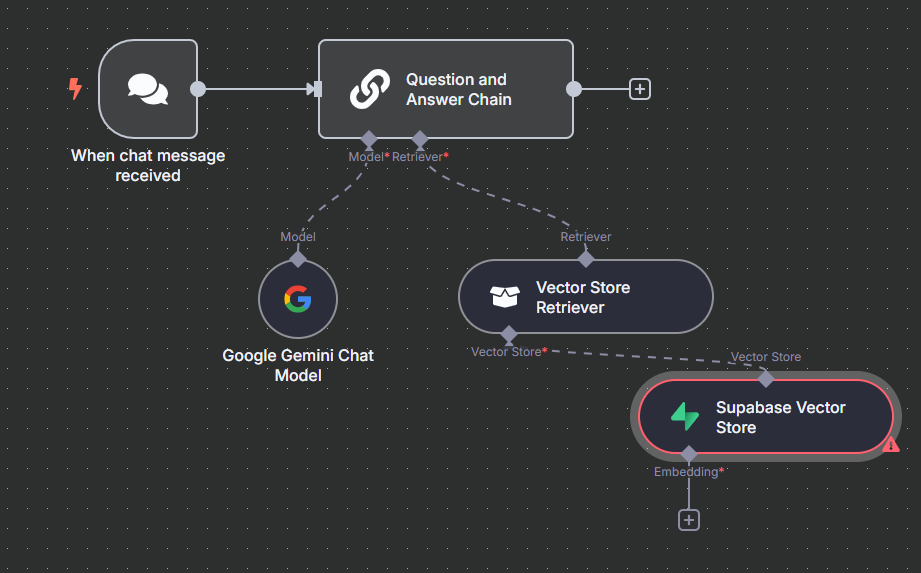
步驟四:設定向量資料庫檢索器
這是 RAG 的核心:設定如何從我們的 Supabase 向量資料庫中檢索資訊。
- 點擊 Q&A Chain 節點右下的 "鬚鬚",選擇 "Vector Store Retriever"。
- 在跳出的視窗中,繼續點擊紅點上的 "+",選擇 "Supabase Vector Store"。
- 設定 Supabase 連線:
- 選擇您的 Supabase 憑證。
- "Table Name" 選擇
nhi_drug_768。 - "Query Name" 改為
match_nhi_drug_768。
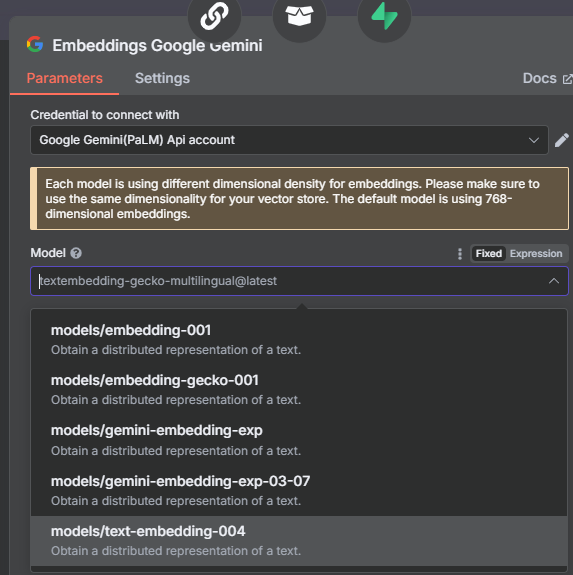
- 設定 Embedding 模型:
- 在 Supabase Vector Store 節點下方的 "鬚鬚" 點擊 "+"。
- 選擇 "Embeddings Google Gemini"。
- 選擇您的 Gemini 憑證,並將 Model 設為
models/text-embedding-004。
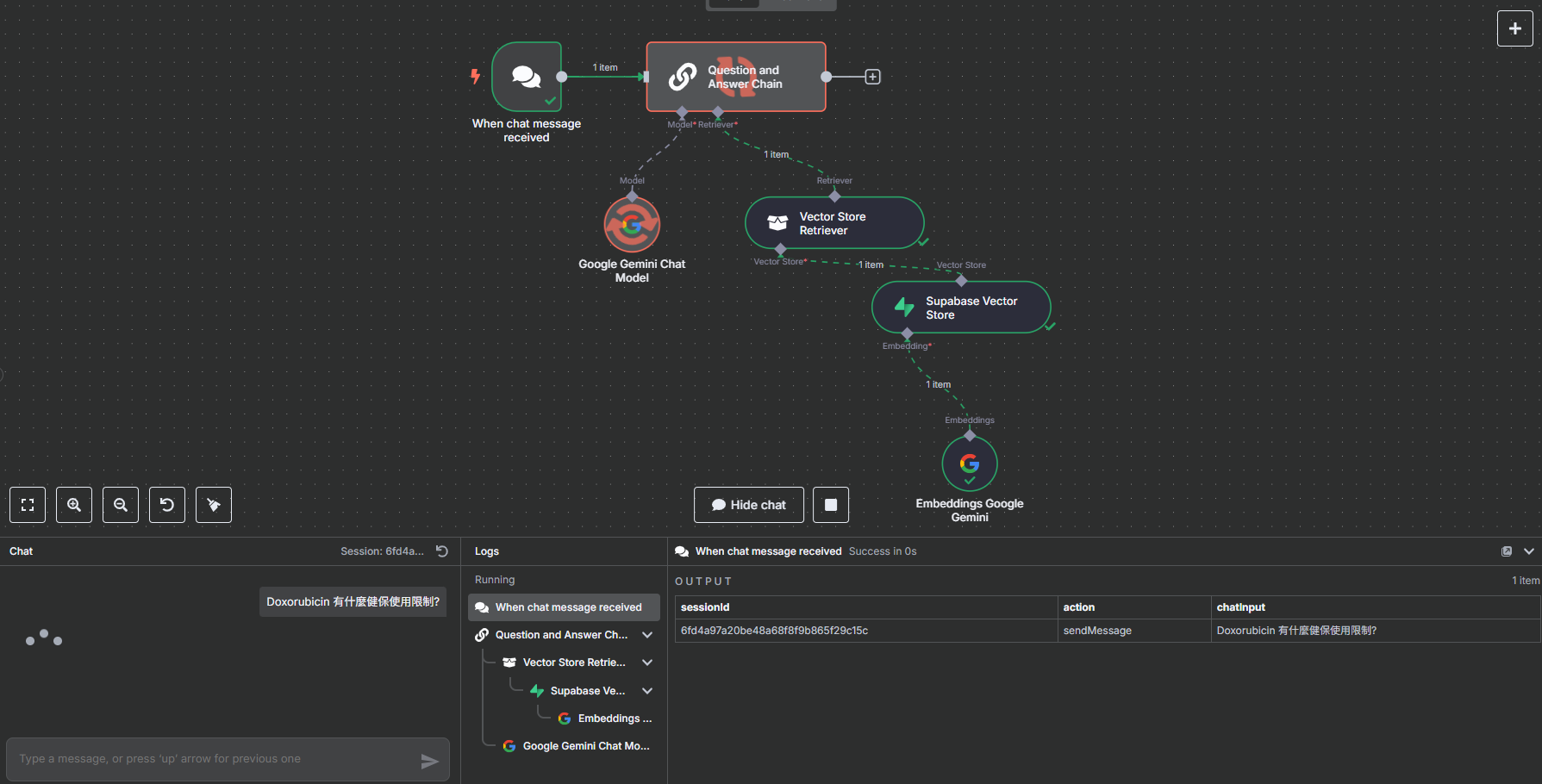
步驟五:開始聊天與驗證
所有節點都設定完畢!現在可以開始與您的 AI 聊天了。
- 點擊畫面下方的橘色按鈕 "Open chat"。
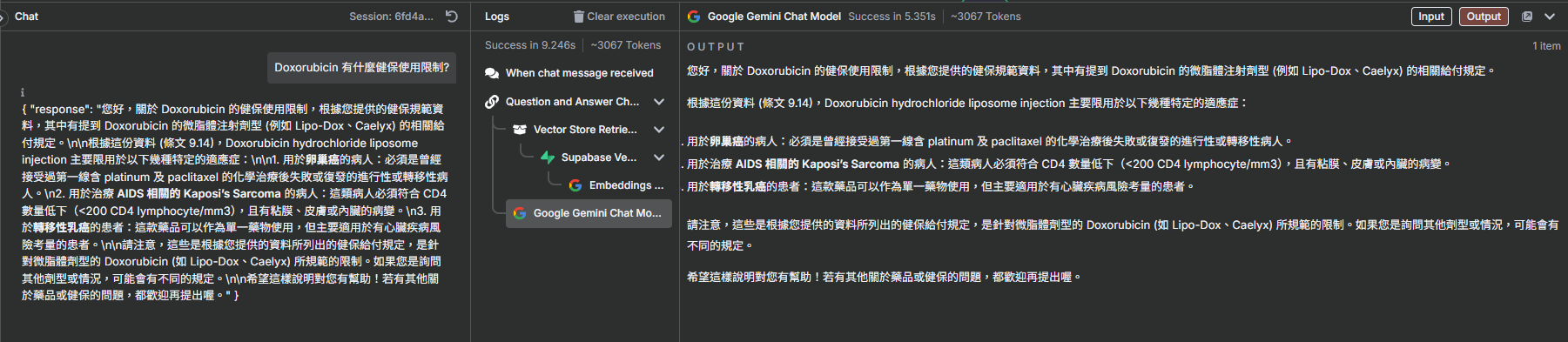
- 在聊天視窗中,輸入您想詢問的健保用藥問題,例如:「Doxorubicin 有什麼健保使用限制?」
- AI 會接收您的問題,轉換為向量後至 Supabase 搜尋,最後將搜尋結果與您的問題結合,生成最終回覆。
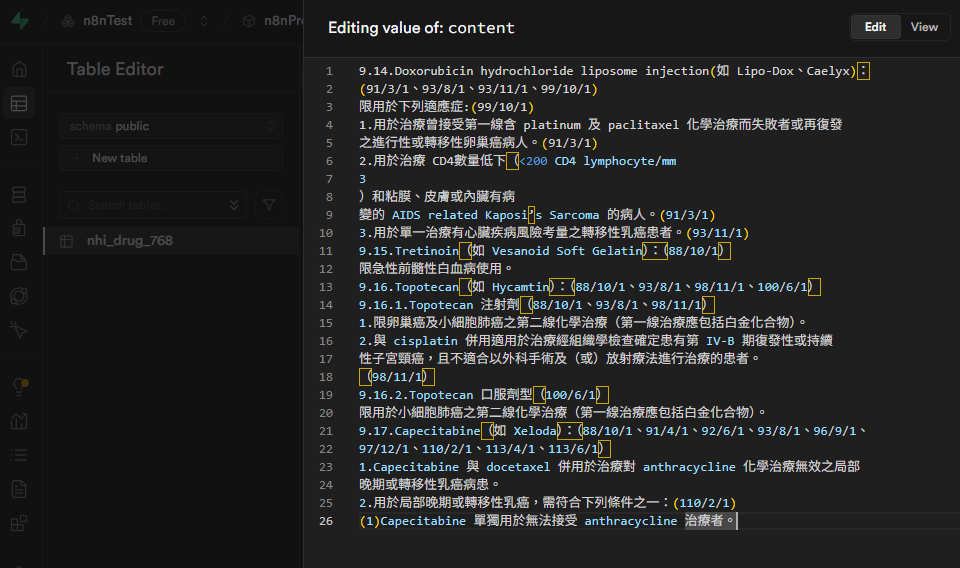
- 您可以比對 AI 的回答與 Supabase 資料庫中的原文,確認其準確性。
系列總結與展望
恭喜您完成了整個 n8n 教學系列!您已經從零開始,成功地建立了一個功能完整的 RAG 應用。回顧整個系列,我們學會了:
- 環境建置: 在本地安裝 n8n。
- 資料庫設定: 建立 Supabase 向量資料庫。
- API 申請: 取得 Gemini API Key。
- 資料寫入: 建立工作流將文件轉換為向量並存入資料庫。
- 資料檢索與生成 (RAG): 建立工作流,讓 AI 根據私有資料回答問題。
您現在所掌握的技能,是打造各種強大 AI 自動化應用的基礎。您可以嘗試替換不同的資料來源 (如 Notion、網頁爬蟲)、探索更複雜的 Prompt Engineering 技巧,或將結果輸出到不同的地方 (如 Email、Slack)。自動化的世界充滿無限可能,期待您創造出更多精彩的應用!