從一句話到完整 PRD:多代理 AI 自動化生成系統
一個結合多個 AI 代理與混合式 RAG 的 n8n 工作流,將一句自然語言需求,轉化為包含規格、使用者故事與測試案例的完整 Confluence 文件。
專案緣起:PRD 撰寫的「三重挑戰」
在醫療資訊(HealthTech)領域,撰寫一份高品質的產品需求文件(PRD)極具挑戰性,通常面臨三大難題:
- 法規遵循的複雜性: 功能必須符合健保署(NHI)的繁瑣規範以及醫療法規(例如管制藥),任何遺漏都可能造成申報問題或病人安全風險。
- 內部知識的壁壘: 新功能需與現有龐大的 HIS 系統無縫接軌,PM 需要深入理解歷史 PRD,確保規格一致性,但這往往耗費大量時間。
- 人力與時間的瓶頸: 從需求分析、規格撰寫、使用者故事拆解到測試案例設計,整個流程高度依賴人工,不僅耗費資源,且產出品質因人而異。
為了解決這些痛點,我設計了這個基於 n8n 的多代理(Multi-Agent)AI 自動化系統,目標是將「一句話需求」轉化為符合內部風格及規範的「PRD初稿」,幫助 PM 在 60 分的基礎上繼續前行。
The Challenge
「撰寫 PRD 是一項高重複性卻不容出錯的工作。將業務需求轉化為技術規格時,常因溝通落差導致規格模糊;且為了符合法規與內部標準,PM 往往需花費大量時間查閱歷史文件,導致核心價值——『產品策略思考』的時間被嚴重壓縮。」
The Solution
「我構建了一個『AI 虛擬產品團隊』。透過 n8n 串接多個 AI Agent,分別扮演架構師、法規顧問與 QA。系統能自動檢索內部知識庫 (RAG),將一句話需求擴寫成包含使用者故事、驗收標準甚至測試案例的完整 PRD,確保規格一致性並節省 80% 的撰寫時間。」
混合式 RAG:讓 AI 擁有「專家大腦」
此系統的核心是「混合式檢索增強生成」(Hybrid RAG)。我們不只使用單一的知識庫,而是建立了三個獨立的 Qdrant 向量資料庫,分別儲存:
- 健保法規知識庫: 包含所有健保署的大量公開條文與作業指南。
- 內部 PRD 知識庫: 涵蓋部門歷史專案中,特意挑選出的產品需求文件。
- 測試案例知識庫: 累積了 QA 團隊精心撰寫的所有 E2E 測試案例。
透過讓不同的 AI 代理查詢指定的「專家大腦」,我們確保 AI 在撰寫文件的每一個環節,都能基於最相關、最權威的上下文,產出既符合法規又遵循內部標準的內容。
理念核心:AI 代理的「數位化分工」
此工作流模擬一個高效的產品開發團隊,由四個各司其職的 AI 代理接力完成任務,實現從需求到文件的端到端自動化。
- AI 商業分析師 (多智能體AI): 它接收使用者的原始需求(例如:「門診口服抗生素最多開 14 天」),並指派任務給兩個專家代理,分別查詢「健保法規」和「內部 PRD」知識庫,最後將三方資訊整合成一份「優化後的需求文件」。
- AI 規格書架構師 (PRD Architect): 接收「優化後的需求」,並大量查詢「內部 PRD 知識庫」學習寫作風格跟架構。它的任務是產出 PRD 的核心章節,包括業務流程圖(Mermaid 語法及渲染圖)、UI/UX 設計草圖 (HTML/CSS) 和 API 規格表,並識別出所有需要開發的「使用者故事標題」。
- AI 使用情境專家 (User Story Specialist): 接收 PRD 主體和「使用者故事標題」列表。它會逐一將標題擴寫成包含前置條件、規格和驗收標準的完整使用者故事表格。
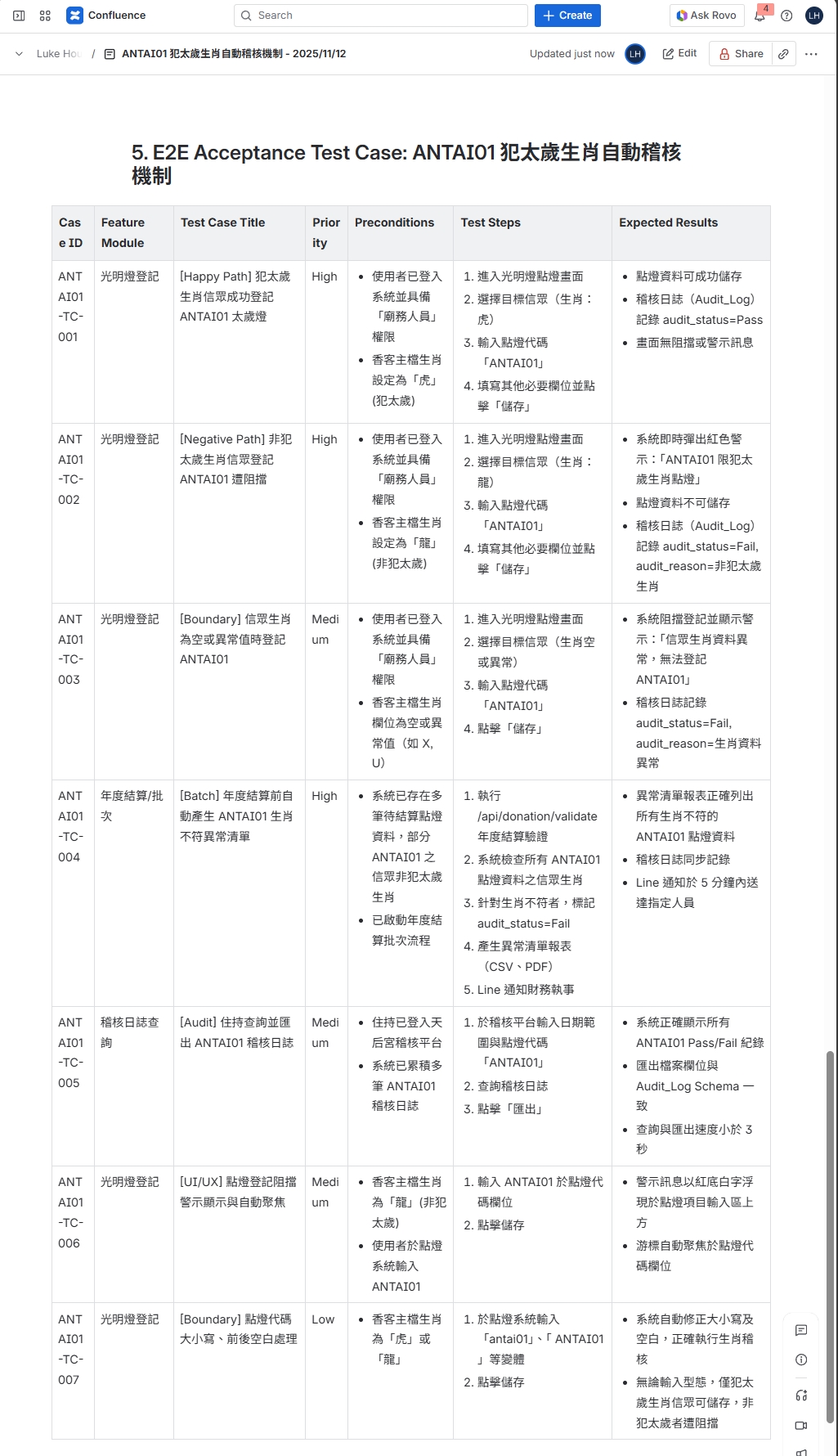
- AI 品保工程師 (QA Engineer): 接收前面產出的所有文件,並查詢「測試案例知識庫」。它的任務是撰寫詳盡的 E2E 測試案例,涵蓋流程情境、正向、負向及邊界測試場景。
- 文件發布 (Confluence Integration): 最後,工作流將所有 AI 生成的 HTML 內容組合起來,自動在 Confluence 上建立一個格式完美的新頁面,完成整個自動化流程。
- 模型分級與成本效益策略 (Tiered Model & Cost-Benefit Strategy): 為了在產出品質與 API
成本之間取得最佳平衡,此工作流根據每個 AI 代理的任務特性,採用了差異化的 LLM 選型策略:
- 深度推理層 (GPT O3): 負責核心邏輯與分析的 AI 協調員與 AI 架構師,採用了專為複雜思考設計的 GPT O3 模型。此模型擅長多步驟的邏輯推理鏈,能更好地分析使用者需求的模糊地帶、解讀法規、並從多個知識來源中進行綜合規劃。雖然速度較慢,但其在深度分析上的優勢確保了 PRD 核心架構的正確性與嚴謹性。
- 快速生成層 (GPT 4.1): 負責結構化內容生成的 AI 故事專家與 AI 品保工程師,則採用了速度更快、更擅長遵循指令的 GPT 4.1 模型。這兩個代理的任務是將上游的規格擴寫成格式固定的表格(使用者故事、測試案例),這正是 GPT 4.1 的優勢所在:高效、流暢地產出長篇的結構化文本,同時能有效控制輸出格式。
企業級資安架構:本地知識庫與私有 LLM 的結合
此系統在設計上將企業級的資訊安全視為最高優先。我們透過以下三項關鍵技術及服務,確保公司最敏感的智慧資產(法規知識、產品規格、測試案例)與使用者輸入的需求,都在一個絕對安全的閉環中處理:
- 本地自動化工作流 (Local n8n): 部署在內部機器上的 n8n 服務,提供了一連串本地化的自動化工作流。
- 本地向量資料庫 (Local Qdrant): 儲存了團隊核心智慧財產的向量資料庫,是部署在內部的機器上。這代表所有 RAG 的檢索過程,都在內部完成,杜絕了知識庫經由外部服務外洩的風險。
- 私有大型語言模型 (Azure OpenAI): 此工作流串接的並非公開的 OpenAI API,而是公司內部部署、透過 Azure 提供的 OpenAI 服務節點。所有的提示(Prompt)與生成內容都在企業私有的雲端環境中進行,符合資料治理與隱私規範。
這個「本地 AI 自動化工作流 + 本地檢索 + 私有雲生成」的混合式架構,讓我們在享受大型語言模型強大能力的同時,也能完全掌控資料的流向,是此解決方案能真正應用於企業核心業務的關鍵。
工作流展示
點擊下方頁籤,查看此工作流的實際運行示意:
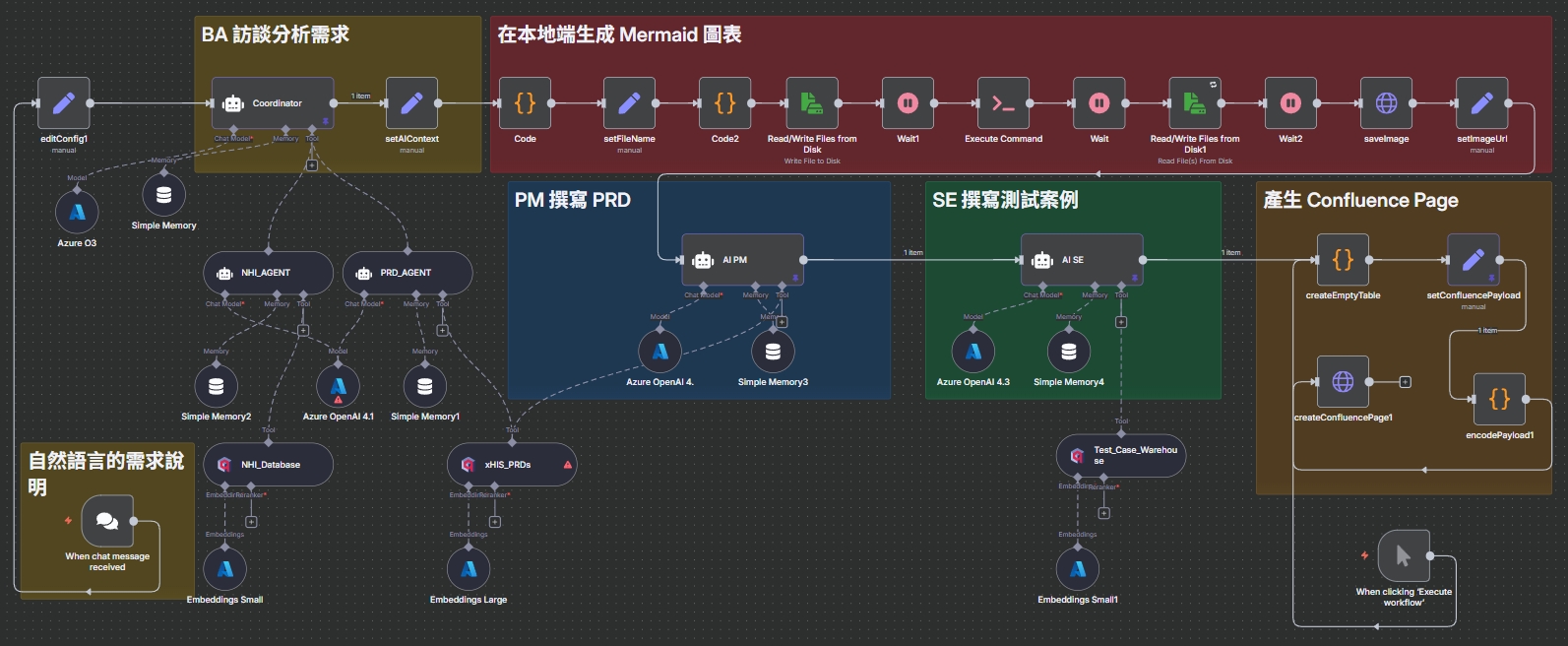
n8n 整體工作流
從一個簡單的聊天視窗觸發,串連起四個 AI Agent,每個 Agent 都有獨立的 Prompt 和指定的工具(向量資料庫),最終透過 HTTP Request 節點將結果寫入 Confluence。
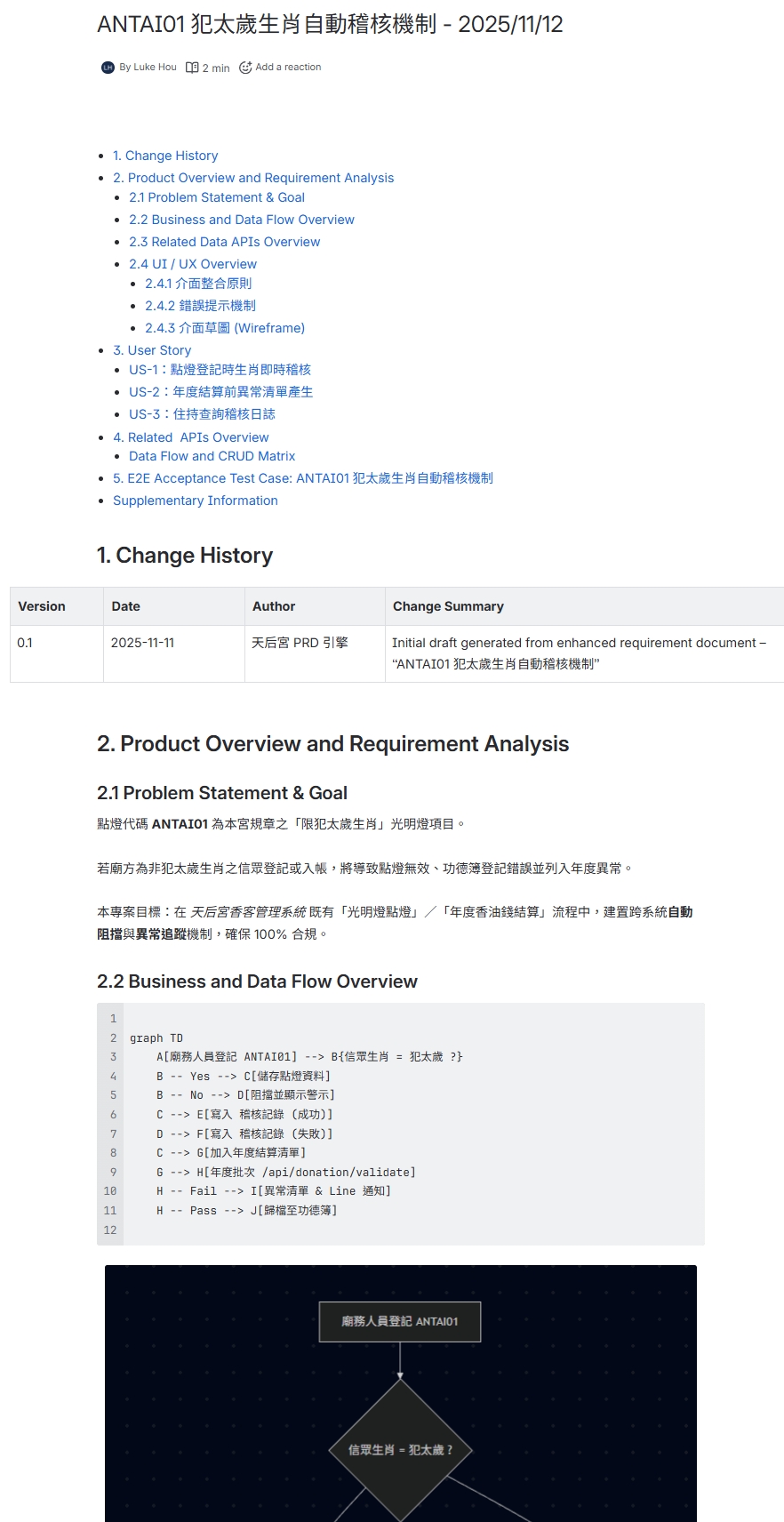
產出成果:結構化的 Confluence 文件
AI 自動將單一需求擴寫成一份包含多個章節的專業 PRD 文件,格式工整,內容詳盡。(點擊放大查看)
Part 1: 目錄
Part 2: 流程圖及UI需求

Part 3: E2E 測試案例
成果與反思:知識工作的「自動化新範式」
這個專案展示了如何透過 AI Agent 的協作,將複雜的知識型工作流轉化為高效、可靠的自動化系統。
-
指數級的效率提升 將原本需要數天甚至一週的 PRD 撰寫、審查、修改流程,縮短至幾分鐘內完成初稿,大幅加速開發週期。
-
確保產出品質與一致性 AI 透過學習大量內部文件,確保每一份產出的 PRD 都符合公司內部的最佳實踐與格式規範,消除了人為的風格差異。
-
知識的傳承與活化 將靜態的文件(法規、舊 PRD)轉化為動態的、可供 AI 隨時查詢的知識庫,實現了組織知識的真正活化與傳承。
-
重新定義 PM 與 QA 的角色 將團隊成員從繁瑣的「文件撰寫者」轉變為「策略制定者」與「品質把關者」,專注於更高價值的創造性工作。