n8n 教學 (九):改造 Chat 工作流,實現本地知識庫問答
發布日期:2025年8月
前言:最後一哩路,讓 AI 開口說「你的」話
恭喜您來到本系列教學的最終章!我們已經成功將知識庫儲存在本地的 Qdrant 資料庫中。現在,我們將完成最後一塊拼圖:改造聊天工作流,讓 AI 能夠從這個私有知識庫中檢索資訊,並根據這些資訊來回答您的問題。本章將引導您設定 Qdrant 檢索節點,結束後,您將擁有一個完全在您掌控之下的、具備私有知識庫的問答機器人。
重要提醒: 如果您的 Gemini API key
綁定在免費方案 (free tier) 且未啟用帳單,則 Gemini 處理的資料可能被用於模型訓練。若涉及機敏資訊且必須使用 Gemini,請務必升級至付費方案,或使用地端
LLM,亦或是公司提供的 API。
步驟一:置換向量資料庫節點
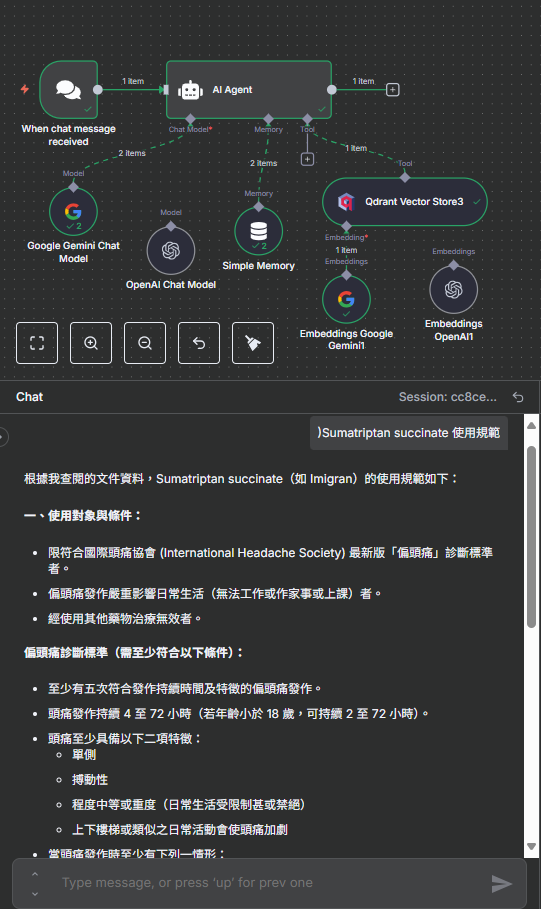
我們的起點是先前建立的聊天工作流。首先,我們需要將雲端的 Supabase 節點替換為本地的 Qdrant 節點。
- 打開您用於聊天的 n8n 工作流。
- 選取並刪除 "Supabase Vector Store" 節點。
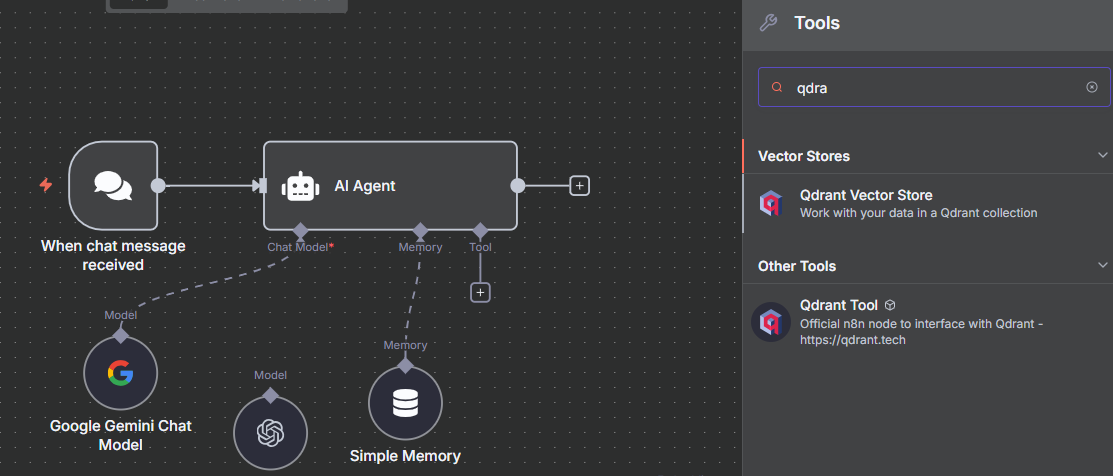
- 在右下角的 "Tools" 面板中,點擊加號,搜尋並加入 "Qdrant Vector Store" 節點。
步驟二:設定 Qdrant 檢索節點
接下來,我們需要詳細設定這個新的 Qdrant 節點,告訴它如何從我們的本地資料庫中查找相關資訊。
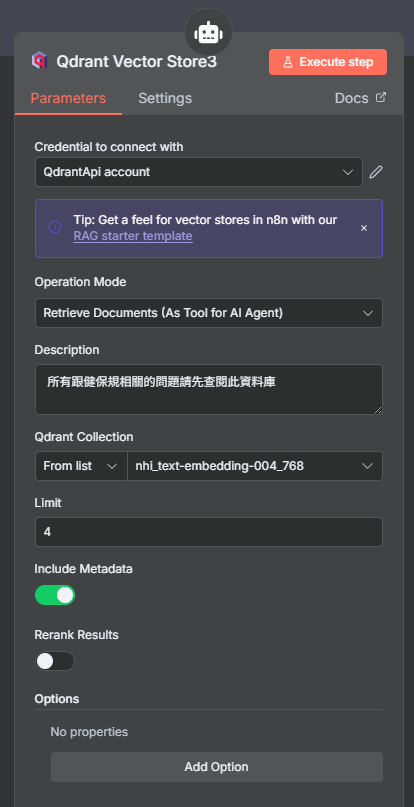
- 點擊開啟 "Qdrant Vector Store" 節點。
- Credential: 選擇您在上一章建立的 Qdrant Credential。
- Operation: 確認操作為 "Search for documents"。
- Collection Name: 輸入我們使用的 Collection 名稱
nhi_text-embedding-004_768。 - Limit: 保持預設值即可,這代表每次檢索回傳的資料筆數。
步驟三:重新連接工作流
設定完成後,需要將 Qdrant 節點正確地整合到現有的工作流中。
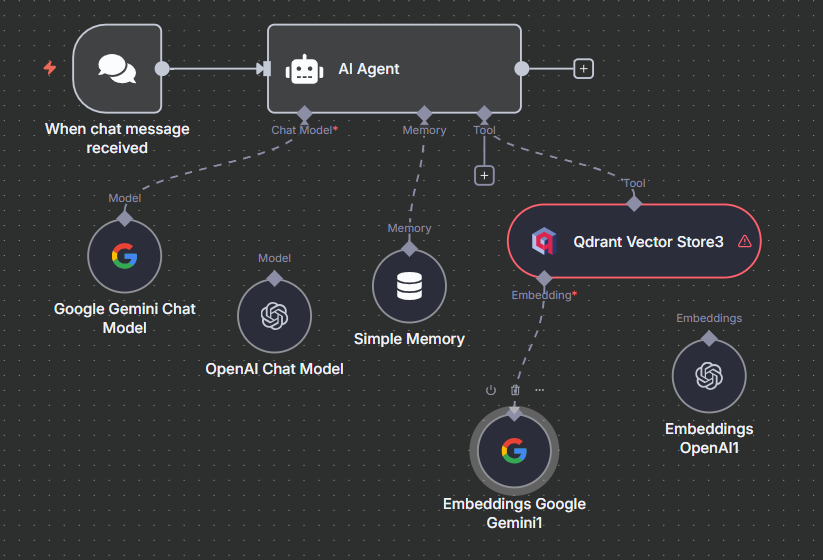
- 關閉節點設定視窗。
- 將 "Qdrant Vector Store" 節點左下角的 "Tool" 接口,連接到 "Google Gemini Chat Model" 節點的圓球上。這一步是告訴 AI 模型,Qdrant 是它可以使用的外部工具之一。
步驟四:啟動聊天並驗證成果
萬事俱備!現在讓我們來實際測試一下,看看 AI 是否能正確地從我們的本地知識庫中找到答案。
- 點擊 "When chat message received" 節點來啟動聊天測試介面。
- 在聊天視窗中,輸入一個與您上傳的 PDF 文件相關的問題。例如:「補充保費的費率是多少?」
- 觀察 AI 的回覆。如果一切設定正確,它應該會根據文件內容給出精確的答案。

重要提醒: 如果您的 Gemini API key
綁定在免費方案 (free tier) 且未啟用帳單,則 Gemini 處理的資料可能被用於模型訓練。若涉及機敏資訊且必須使用 Gemini,請務必升級至付費方案,或使用地端
LLM,亦或是公司提供的 API。
本章總結與系列回顧
太棒了!您已經成功完成了整個系列教學。您不僅建立了一個功能完整的 RAG 應用,更重要的是,您實現了它的完全私有化與在地化。讓我們回顧一下這趟旅程:
- 從零開始,在本地建置了 n8n 的運行環境。
- 學會申請 Google Gemini API,並將其強大的語言模型整合至工作流中。
- 掌握了兩種向量資料庫的操作:雲端的 Supabase 與在地化的 Qdrant。
- 建立了自動化的工作流,能將文件(如 PDF)處理、向量化並存入資料庫。
- 最終,打造了一個能與您的私有知識庫互動的 AI 聊天機器人。
您現在擁有的不僅是一套工具,更是一套解決問題的方法論。希望這個系列能為您的 AI 自動化之旅提供一個堅實的起點。未來還有無限可能,期待您創造出更多精彩的應用!