n8n 教學 (二):Supabase 申請及建立向量資料庫
發布日期:2025年5月
前言
在上一篇文章中,我們成功建置了 n8n 的本地環境。接下來,我們需要一個地方來儲存和管理我們的資料。本章將引導您完成 Supabase 的帳號申請,並建立一個強大的向量資料庫,這將是我們後續進行 AI 相關應用的核心基礎。
重要提醒: 如果您的 Gemini API key
綁定在免費方案 (free tier) 且未啟用帳單,則 Gemini 處理的資料可能被用於模型訓練。若涉及機敏資訊且必須使用 Gemini,請務必升級至付費方案,或使用地端
LLM,亦或是公司提供的 API。
步驟一:註冊 Supabase 帳號
首先,前往 Supabase 官方網站並開始註冊流程。
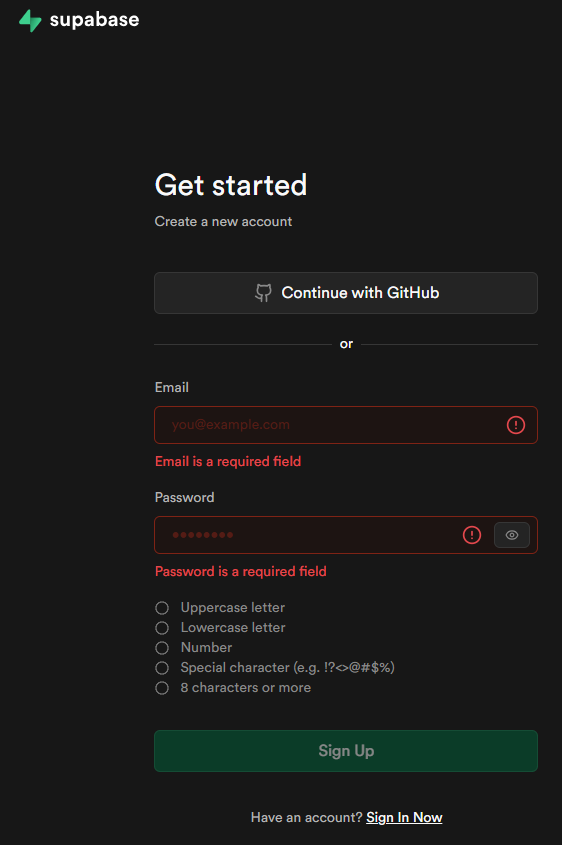
點擊 "Start your project",然後選擇 "Sign Up Now" 使用 Email 進行註冊。填寫您的信箱和密碼,並完成信箱驗證。
步驟二:建立組織與專案
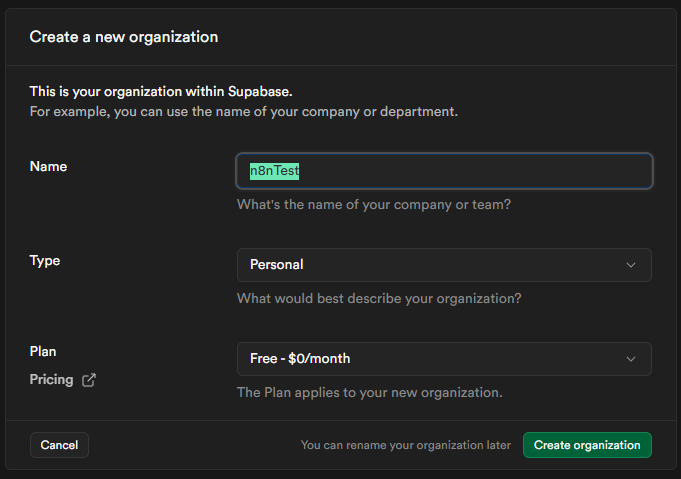
登入後,首先需要建立一個「組織 (Organization)」,您可以將其視為一個工作區。接著,在組織內建立一個新的「專案 (Project)」。
- 點擊 "New Organization",輸入組織名稱 (例如:
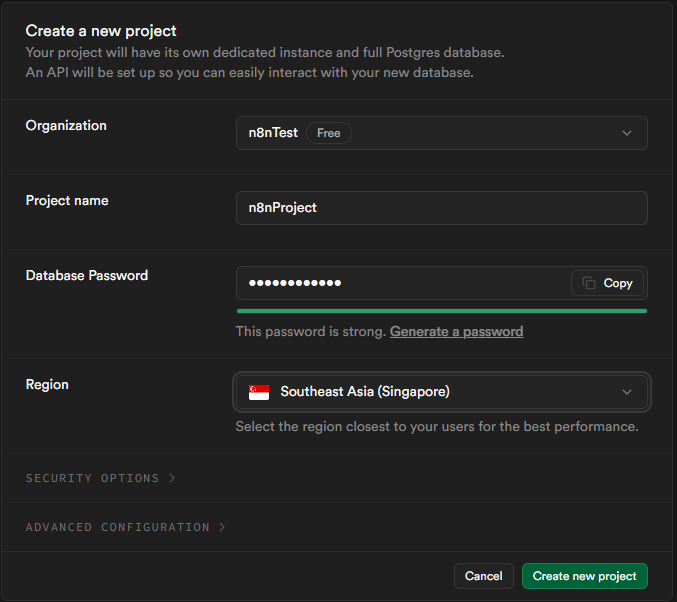
n8nTest),點擊 "Create Organization"。 - 接著建立新專案,輸入專案名稱 (例如:
n8nProject)。 - 請務必設定一組安全的資料庫密碼並妥善保存。
- 選擇離您最近的 Region (區域) 以獲得較低的延遲。
- 點擊 "Create new project"。
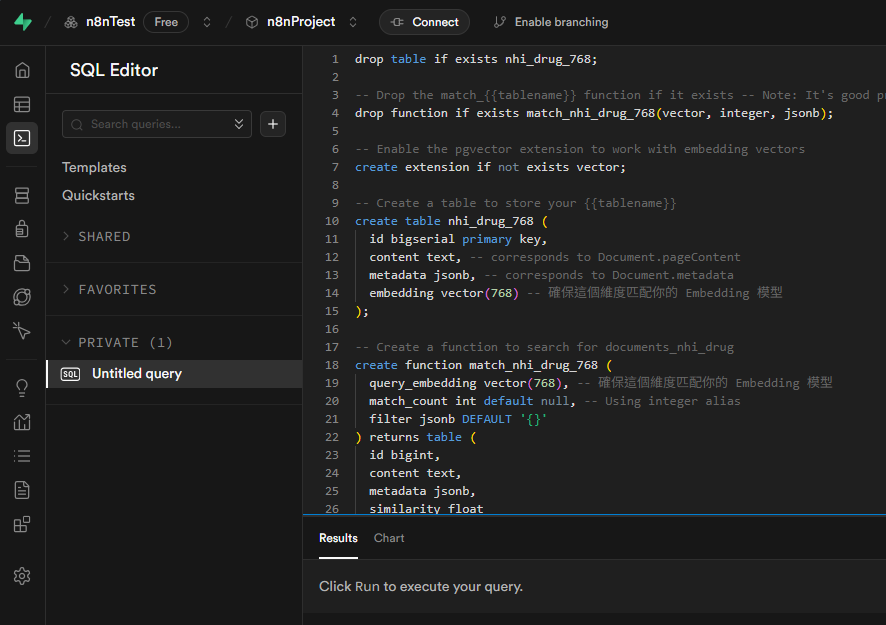
步驟三:建立向量資料表
專案建立後,我們需要透過 SQL 來啟用 pgvector 擴充功能並建立儲存向量的資料表。
- 從左側選單進入 "SQL Editor"。
- 點擊 "+ New query" 來新增一個查詢。
- 將下方的 SQL 語法貼入查詢編輯器中。這段語法會:
- 啟用
vector擴充功能。 - 建立一個名為
nhi_drug_768的資料表,包含content、metadata和embedding(768 維) 欄位。 - 建立一個名為
match_nhi_drug_768的函式,用於後續的向量相似度搜尋。
- 啟用
-- Enable the pgvector extension to work with embedding vectors
create extension if not exists vector;
-- Create a table to store your documents
create table nhi_drug_768 (
id bigserial primary key,
content text, -- corresponds to Document.pageContent
metadata jsonb, -- corresponds to Document.metadata
embedding vector(768) -- Ensure this dimension matches your embedding model
);
-- Create a function to search for documents
create function match_nhi_drug_768 (
query_embedding vector(768),
match_count int,
filter jsonb DEFAULT '{}'
) returns table (
id bigint,
content text,
metadata jsonb,
similarity float
)
language plpgsql
as $$
#variable_conflict use_column
begin
return query
select
id,
content,
metadata,
1 - (embedding <=> query_embedding) as similarity
from nhi_drug_768
where metadata @> filter
order by embedding <=> query_embedding
limit match_count;
end;
$$;貼上語法後,點擊 "Run" 按鈕執行。成功後,您會在下方看到 "Success. No rows returned" 的訊息。
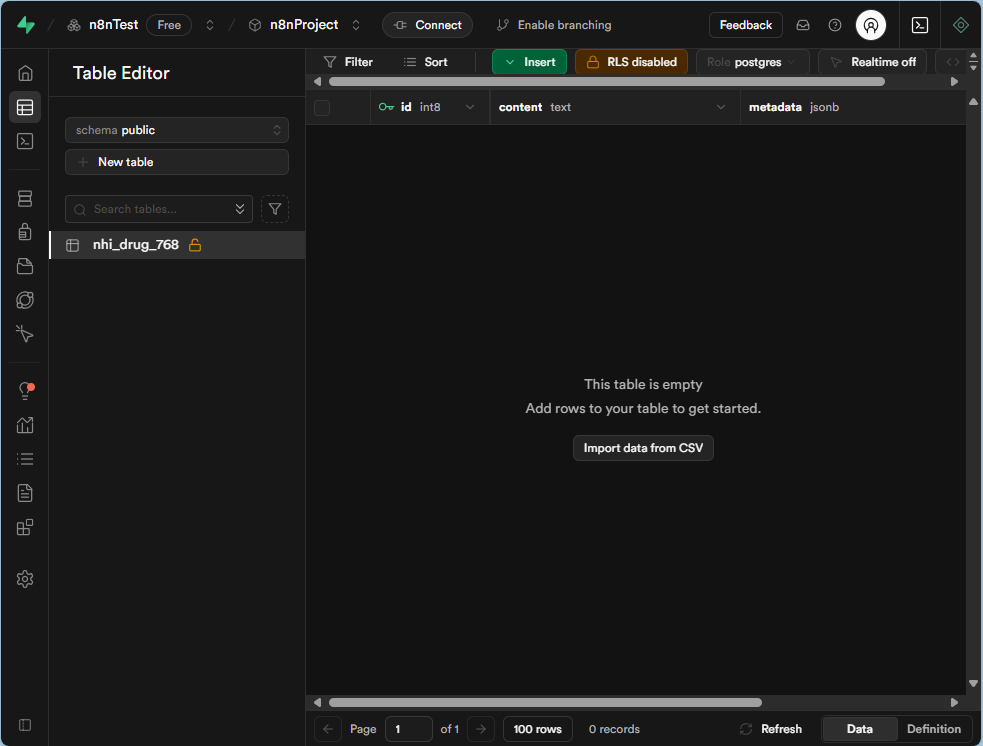
步驟四:啟用 RLS (Row Level Security)
為了資料安全,我們必須為新建的資料表啟用 RLS。
- 從左側選單進入 "Table Editor",您會看到剛剛建立的
nhi_drug_768資料表。 - 點擊資料表名稱,您會看到 "RLS is not enabled" 的提示。
- 點擊 "Enable RLS" 按鈕,並在彈出視窗中確認啟用。
- 注意: 啟用 RLS 後,預設會拒絕所有存取,我們需要在後續步驟中設定適當的 Policy 才可讓 n8n 存取。
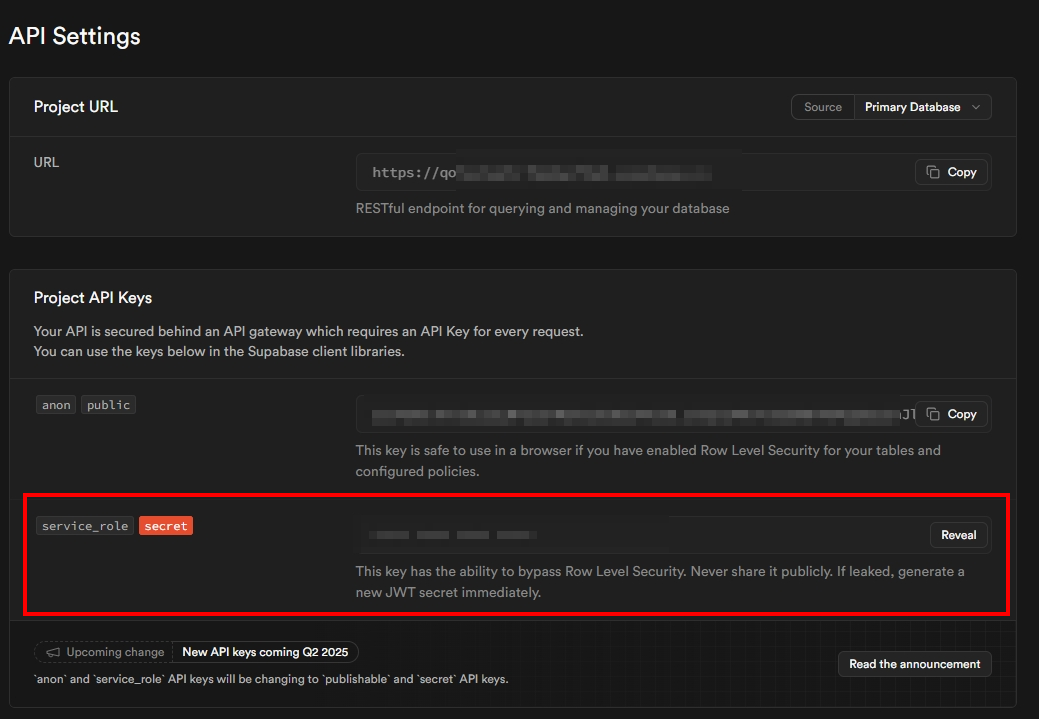
步驟五:取得 API 金鑰
最後,我們需要取得專案的 API 金鑰,以便 n8n 能夠連接到 Supabase。
- 從左側選單進入 "Project Settings" (專案設定)。
- 選擇 "API" 分頁。
- 在 "Project API Keys" 區塊,找到
service_role的金鑰。 - 點擊 "Reveal" 後再點擊 "Copy" 來複製這組金鑰。
極度重要:
service_role 金鑰擁有您資料庫的完整權限,等同於最高管理員。請務必將其存放在安全的地方
(如密碼管理器),絕對不要外洩或直接寫在前端程式碼中。
本章總結
做得好!您已經成功設定好 Supabase 並為我們的 AI 應用準備好了一個向量資料庫。回顧一下本章重點:
- 完成 Supabase 帳號註冊、組織與專案的建立。
- 學會使用 SQL Editor 啟用
pgvector並建立客製化的資料表與搜尋函式。 - 為資料表啟用 RLS,提升資料庫的安全性。
- 取得並妥善保存了具備完整權限的
service_roleAPI 金鑰。
在下一篇教學中,我們將會介紹 如何申請 Gemini API Key,為我們的自動化流程注入強大的 AI 生成能力。